
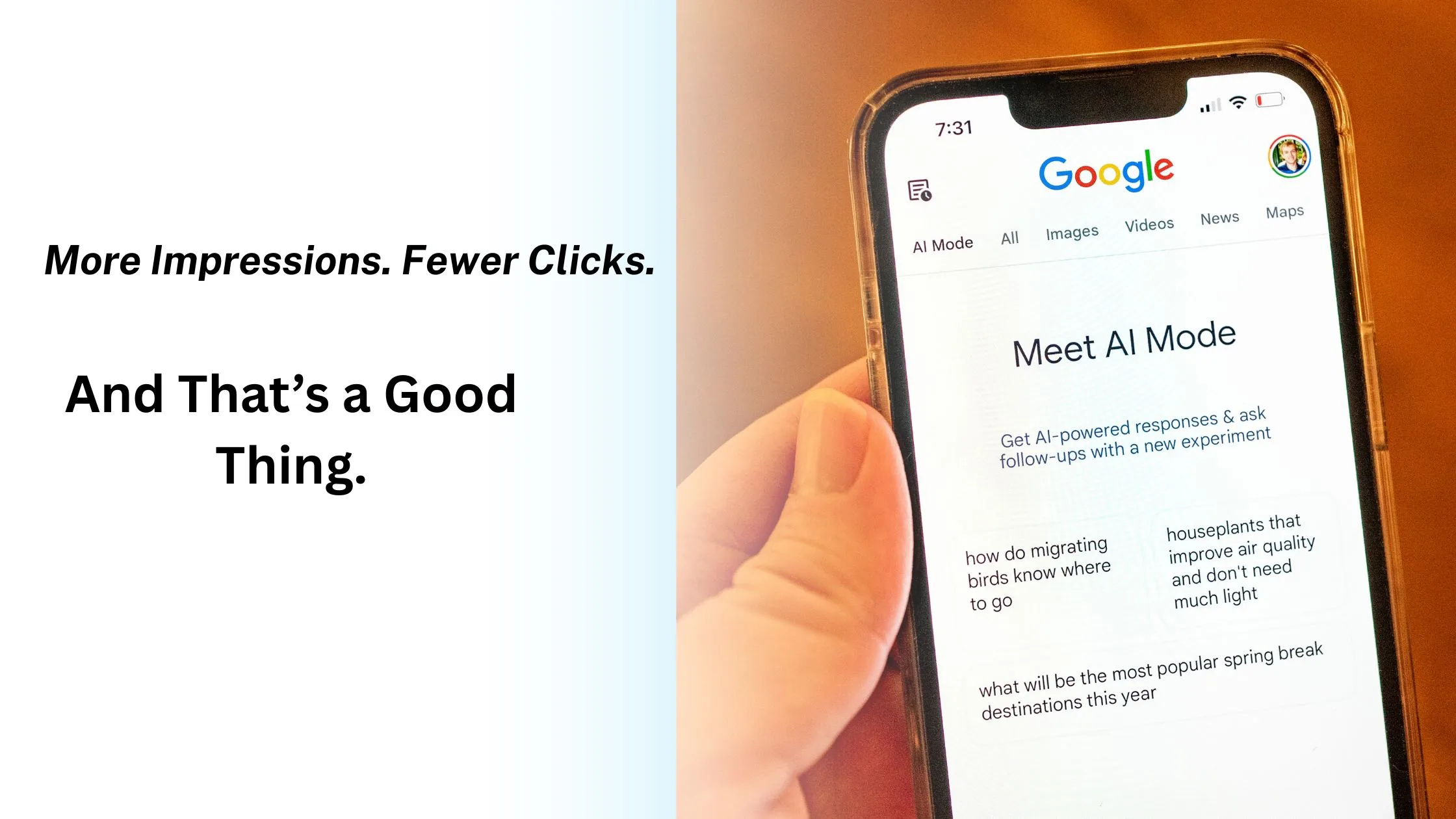
There was a time when SEO success could be distilled into a few simple metrics: rankings, impressions, and click-through rate (CTR). The logic was almost too clean , if your page showed up more and your CTR declined, it was seen as a warning. A signal that users weren’t finding your content compelling enough to click. And for the most part, that interpretation made sense , in a world of static blue links, every impression was a true opportunity, and every drop in CTR felt like a missed one.
But that world is gone.
Search has evolved. The classic 10-blue-link layout has been fragmented, restructured, and overtaken by AI Overviews, rich SERP features, and semantic relevance engines that no longer rely solely on keywords. Today, impressions are no longer about single-slot visibility; they’re about multi-surface representation. And if you’re seeing your CTR dip while impressions rise, you might be witnessing not a failure , but the early signs of semantic authority.
This post is an exploration of that shift. We’ll unpack how AI-powered search redefines visibility, why CTR is a limited lens in this new paradigm, and how understanding vector-based retrieval, cosine similarity, and relevance engineering can give you a better compass in today’s search landscape.
Traditional CTR: Simpler Times, Simpler Metrics

Let’s begin with what CTR used to represent.
In the traditional SERP, Google displayed 10 organic blue links per page, with occasional additions like featured snippets or video carousels. If your page ranked, it would occupy exactly one position per query. A user searching “best email marketing tools” might scroll through those 10 links, and if they clicked yours, that was a clean click , one impression, one action.
CTR in this world was tightly tied to ranking. First position might earn 30–35% CTR, second slightly less, and so on down the line. The math was tidy, and optimization efforts were largely centered around improving that position.
This was a world where CTR was diagnostic. A sudden drop suggested a meta title issue, a mismatch in search intent, or new competition claiming your spot. The equation was linear: rank better → earn more clicks.
But this model begins to break when the structure of the SERP itself changes , and that’s exactly what’s happening now.
The Fragmented SERP: Welcome to the Multi-Slot Reality
Modern search results are no longer a static grid of links. They’re dynamic, AI-injected, and stitched together from multiple content surfaces , often surfacing the same page or same brand multiple times.
Imagine you publish a comprehensive guide on “how to secure a WordPress website.” That single page might:
- Be cited inside the AI Overview box
- Show up in the traditional organic results
- Be referenced in a People Also Ask (PAA) box
- Trigger a FAQ-rich snippet via schema
All of these are individual impressions recorded in Google Search Console , sometimes from the same query session. Which means one user might generate three or four impressions for the same content piece… and still only click once (or not at all).
This is where we see the divergence: impressions go up, CTR goes down, and yet visibility increases.
Why? Because Google isn’t matching your content based on keyword strings anymore. It’s matching meaning.
Let’s pull back the curtain.
How Vector Embeddings Rewire Search Behavior
Today’s AI-powered engines don’t “look” at words the way humans do. They operate in semantic space , converting both queries and content into vectors using embeddings.
Think of vector embeddings as coordinates in a multi-dimensional universe. Each dimension represents a conceptual feature , and the closer your content vector is to the query vector, the more semantically aligned they are.
Search engines now project queries into this space, then retrieve content vectors that lie closest , not necessarily the ones that match exact terms. This is where techniques like cosine similarity come in. Cosine similarity measures the angle between two vectors , a smaller angle means stronger similarity. It’s like asking: How parallel is your content’s intent to what the user is actually asking for?
So if your content sits at the semantic center of a topical cluster, it may surface in multiple retrieval zones of the SERP , not because it’s over-optimized, but because it’s relevant in more ways than one.
The result? A page that might have earned one impression in the past now earns three or four. CTR declines, but exposure multiplies.
Relevance Expansion and the Math Behind CTR Declines
Let’s make this real.
Suppose someone searches for “best security plugin for WordPress.” Your article is cited:
- In the AI-generated answer box
- As a blue link in the organic results
- As the source of a PAA entry: “What is the best plugin for WordPress security?”
That’s three impressions in one user session. Let’s say the user clicks only once , your CTR is 33%. In the old world, that same click would’ve yielded a 100% CTR.
Did your content suddenly become less compelling? Of course not. It became more present.
This is the core of what we call relevance expansion , your content is being recognized as relevant across multiple semantic frames, not just one. And when that happens, your impression count inflates, but not necessarily your clicks.
CTR drops. But not because you’re failing , because you’re succeeding at semantic breadth.
Zero-Click Visibility: The Billboard Effect
Now let’s get into the most misunderstood concept in post-AI SEO: zero-click visibility.
In a world of AI Overviews, direct answers, and voice search, and even visual search, users often get their answer without clicking. And yet, your brand or domain might still be prominently cited. This is what I call the billboard effect.
Think of it this way: You’re driving down a highway, and you see a huge billboard for a law firm. You don’t need a lawyer today, so you don’t take any action. But the name sticks. And when a friend asks for a recommendation next week? You remember it.
Appearing in multiple locations across a SERP , especially in AI summaries or PAA answers , is like owning multiple billboards on the same stretch of digital highway. Users may not click now, but the brand impression is made.
And search engines notice that too.
When a domain is cited repeatedly across search features, it signals something to the ranking systems , not just that the content is relevant, but that it’s trusted, authoritative, and contextually consistent.
You’re not just being indexed; you’re being endorsed.
The Deeper Signal: Semantic Trust and Entity Strength
What does this mean long-term?
It means you’re becoming a known entity , not in the buzzword sense, but in the literal, Google Knowledge Graph sense. The more your content is retrieved across multiple semantic angles, the stronger your entity profile becomes.
This is what powers the idea of relevance engineering , shaping your site’s architecture and content strategy to align not with individual keywords, but with conceptual proximity to search intents.
It’s no longer about optimizing a page for “best email marketing tools.” It’s about creating multi-dimensional value around email automation, newsletter performance, deliverability best practices, and MarTech integrations , so that when the query morphs, your content stays central.
Over time, you’re not just ranking. You’re being chosen , repeatedly , as the semantic fit.
And that kind of exposure doesn’t always result in a click. But it does result in trust.
Making Sense of GSC in the AI Era
Google Search Console wasn’t designed with LLM retrieval in mind. It still reports impressions based on surface-level placements, whether in organic listings, AI Overviews, People Also Ask modules, or other SERP features. This creates what we might call a positive misalignment: content visibility expands, but CTR metrics shrink. At a glance, this might seem like a performance drop. In reality, it’s often a reflection of broader semantic reach.
To navigate this shift, don’t just stare at CTR in isolation.
Instead:
- Filter your queries by intent category (informational, commercial, branded)
- Use regex filters to isolate long-tail variants
- Track growth in non-click impressions over time
- Cross-reference your GSC with tools like AlsoAsked or Glimpse to visualize question-based visibility
You’ll often find that the queries generating impressions without clicks are still highly valuable; they’re informational entry points, brand reinforcers, or top-of-funnel touchpoints. And thanks to a recent update, it’s now easier to make sense of them.

In June 2025, Google began rolling out dedicated AI Mode traffic data within Search Console. This new reporting distinguishes between impressions and clicks coming from AI Mode versus standard organic results, using adjusted position rules and feature tagging. While still in its early stages, this update allows SEOs to see how their content contributes to AI summaries and citations directly, offering new clarity into a previously opaque part of the SERP.
Optimizing for Semantic Visibility: Engineering Relevance in AI-Powered Search
In the AI-native SERP, ranking isn’t about showing up once for a primary keyword, it’s about being retrieved consistently across the dozens of sub-intents that search engines now parse behind every query. Gemini and other LLM-powered systems don’t think in URLs. They think in reasoning paths, using embeddings, context expansion, and passage-level citations to surface the most semantically aligned information.
To earn visibility in that environment, traditional SEO playbooks aren’t enough. What’s required now is semantic engineering, a methodical, model-aware way of shaping your content and structure to ensure your site is retrievable, not just indexable.
From Keyword Targets to Semantic Matrixes
The first step is rethinking how queries work.
A traditional keyword like “how to reduce SaaS churn” is no longer a single opportunity. When that prompt hits a model like Gemini, it gets expanded into a series of synthetic queries: What is a normal churn rate? What causes churn in onboarding? How do retention metrics vary by cohort?
LLMs generate these subqueries internally as part of the reasoning process, and they retrieve content based on how well it addresses each component, not just the main question. This means your content has to perform well not just at the topic level, but across the semantic matrix of related ideas.
If you think of each synthetic subquery as a column, and each passage from your content as a row, you get a working mental model: a query–passage matrix. Each cell in that matrix has a score, often based on cosine similarity between the query and the passage embeddings. The higher the score, the more likely your passage is to be retrieved. The lower the score, the more likely it is to be ignored in favor of a competitor.
This is why topical coverage alone isn’t enough anymore. You need to ensure your content matches how the LLM perceives relevance at a vector level.
Passage-Level Embeddings and Retrieval Simulation
Once you’ve mapped the subqueries, the next step is to analyze how well your content performs across them.
Start by extracting all passages from your target content, either by logical section breaks or fixed-length chunking. Then generate embeddings for both the subqueries and the passages using a high-quality model. OpenAI’s text-embedding-3-large or Google’s textembedding-gecko are both suitable, depending on whether you’re testing against GPT or Gemini behaviors.
By comparing the vectors through cosine similarity, you can identify whether your passages are semantically close to the model’s expectations, or whether they need to be revised.
This is the layer of optimization that no commercial SEO tool offers today. Passage scoring, not page-level ranking, is what determines visibility in AI Mode.
If you want to go further, simulate a retrieval-augmented generation (RAG) setup using frameworks like LlamaIndex or LangChain. You can load your content into a local vector store, feed in the queries, and observe which passages get selected. This gives you an approximation of what an LLM would “see” and “choose” when building its response.
What you’re doing here is no longer just optimizing content for users. You’re optimizing passage retrievability for machines, machines that reason through chunks of knowledge, not whole documents.
Reinforcing Semantic Signals Within Your Site
Most internal linking is designed to guide crawl or distribute equity. In this new context, internal links do something more valuable: they define semantic relationships between ideas.
If your article on churn links to detailed breakdowns of onboarding, product adoption, customer health scores, and expansion revenue, it tells the model that you’re not just covering a topic, you’re mapping its entire ecosystem.
This internal signal shaping helps LLMs see your domain as entity-dense, meaning your site isn’t just producing content, but modeling the concepts themselves. It becomes easier for Gemini to find multiple relevant passages from your domain, which increases both citation likelihood and multi-surface representation.
Schema Is Still Relevant, but Now for Retrieval, Not Snippets
Structured data, FAQ, HowTo, and Product schema, still matters, but not for the same reasons. In a blue-link world, schema was used to trigger snippets and increase CTR. In an AI-mode world, schema becomes another way to train the model on content type and context.
It helps LLMs understand that a section is a step-by-step process, or that an answer is user-facing and intent-fulfilling. This improves your retrievability across multiple SERP surfaces, even if clicks never happen.
Instead of thinking of schema as a ranking tactic, treat it as input enrichment, a signal that helps the model classify, chunk, and cite your content correctly.
Testing Across Models: Retrieval Isn’t Universal
Even if you’re focused on Google’s AI Mode, it’s smart to test how your content appears across other retrieval engines like Perplexity, Claude, or ChatGPT with browsing. Each of these systems uses its own vector store, its own scoring model, and its own assumptions about what relevance means.
Ask yourself: is my brand being cited? If so, which passages? If not, what kinds of sources are preferred? Are the answers citing data, opinion, walkthroughs, or entity references?
This kind of competitive benchmarking gives you qualitative insight into how your domain is positioned semantically, not just whether it ranks.
Conclusion: Reframing CTR for the Modern Search Reality
It’s time we stopped treating CTR as the holy grail of SEO success. It was a useful metric in the keyword era , but in the vector age, it’s one piece of a much larger puzzle.
Rising impressions and falling CTR aren’t signs of decay , they’re often signals of expansion. A sign that your content is being recognized across contexts, featured across touchpoints, and trusted by the most powerful retrieval engines in history.
The true north in this environment isn’t clicks. It’s credibility, coverage, and contextual dominance.
So next time your dashboard shows a dip in CTR, ask yourself a better question:
Are you losing relevance , or finally becoming semantically undeniable?

{kind=link}